Unstructured Data & Natural Language Processing
Keith Dillon
Spring 2020
Topic 1: Introduction
(Unstructured Data & Natural Language) Processing¶
This is a class in the major problems and computational methods for exploiting natural language and similarly "unstructured" data types,
Examples:
- Text
- Digitized speech signals
- DNA sequences
- code (and related: bytecode, assembly)
We will be heavily emphasizing text as the largest source of methodology and arguably broadest application currently. But we will also devoting a great deal of time to other data types (except speech signals).
Prerequisites¶
Programming skills. We will be using Python which is easier than most any other language you know. Python will be the easiest thing you need to learn in Data Science. Your speed at programming will greatly determine how much free time you have in life here. So if you find homeworks taking a very long time, you need to get better at programming.
DSCI 6001 and 6002: Linear algebra, probability & statistics, and their application in code.
Grading¶
- Quizzes/Homework/Labs/Participation - 10%
- Midterm I - 20%
- Midterm II - 30%
- Final Exam - 40%
Notes vs. Slides¶
Slides are a prop to help discussions and lectures, not a replacement for notes.
Math does not work well via slides. Derivations and problems will be often be given only on the board, requiring note-taking.
If you have a computer science background this is a skill you may need to re-learn.
When you ask "what will be on the exam", I will say "the topics I emphasized in class".
Attendance¶
"The instructor has the right to dismiss from class any student who has been absent more than two weeks (pro-rated for terms different from that of the semester). A dismissed student will receive a withdrawal (W) from the course if they are still eligible for a withdrawal per the University “Withdrawal from a Course” policy, or a failure (F) if not." - Student Handbook
If you don't attend class you are responsible for learning the material on your own.
If you are becoming a burden on the class due to absences I will have you removed.
Participation¶
Active-learning techniques will be used regularly in class, requiring students to work individually and/or with other students.
Refusal to participate (or consistent failure to pay attention) will be treated as absence from class and ultimately lead to dismissal from the class.
Project-based Learning¶
This is not typical projects, where you pick something you know how to do. Or practice work to repeat material done in class.
It means challenging projects you don't know how to solve yet. Then you may either be led to figure it out, or you may be given the solution now that you are better prepared to understand the difficulties the solution addresses.
You may find it frustrating at times.
You may need to get stuck and sleep on it, or ask for advice. If you wait until the last minute you will fail to finish.
Texts¶
“Speech and Language Processing” 3e draft, Dan Jurafsky and James H. Martin 2019. https://web.stanford.edu/~jurafsky/slp3/
“Hands-On Machine Learning with Scikit-Learn and TensorFlow, Concepts, Tools, and Techniques to Build Intelligent Systems”, Géron, O'Reilly 2017. (new edition coming very soon)
Topics (abridged, see syllabus)¶
- Basic text processing
- Classical NLP tasks
- The prob & stat behind NLP
- Machine Learning for NLP
- Deep Learning for NLP
"Unstructured" Data¶
https://en.wikipedia.org/wiki/Unstructured_data
A misleading term, which means data which is not formatted nicely into some kind of data structure which is easily accessed by computer.
Structure = relationships between parts.
Clearly natural language and the other data types listed are filled with structure. That is where most of the information is contained.
What is NLP?¶

NLP, aka "What happened to the numbers?"¶

The goal of the NLP is to convert letters, words, and ideas into numbers.
Once we have the numbers we use math and machine learning.
The raw materials for a revolution¶
1) Data: There is huge wealth of human knowledge that has been digitized.
2) Hardware: parallel computing
3) Algorithms: A combination of CS, ML, linguistic techniques; scalable algorithms
What is Un-Natural Language?¶
... Artificial languages

Why NLP is hard:¶
1) Ambiguity: There are many different ways to represent the same thing.
2) Humans don't consciously understand language.
3) Language is inherently very high dimensional and sparse. There are a lot of rare words.
4) Out of sample generalization. New words and new sentences all the time.
5) Language is organized in a hierarchical manner. Characters -> words -> sentences -> documents ... Which level do we target?
6) Order and context are extremely important. "Dog bites man" and "Man bites dog" have vastly different meanings even though they differ by a very small amount.
7) Computers are extremely good at manipulating numbers, but they are extremely weak at words (and completely suck at manipulating symbols/concepts).
II. Software Tools¶
Install Jupyter, etc.¶
Ideally using Anaconda: https://www.anaconda.com/download/
Or via command line:
conda create -n dsci6004 python=3.7
conda activate dsci6004
conda install nltk ftfy
conda install -c conda-forge textblob
conda install jupyter matplotlib numpy scipy scikit-learn pandas
conda install tensorflow
conda install keras
Or from within Anaconda-Navigator using GUI.
Plan B: Cloud-based Notebooks¶
Google CoLab: https://colab.research.google.com/notebooks/welcome.ipynb
Kaggle Kernel: https://www.kaggle.com/kernels
Jupyter - "notebooks" for inline code + LaTex math + markup, etc.¶
A single document containing a series of "cells". Each containing code which can be run, or images and other documentation.
- Run a cell via
[shift] + [Enter]or "play" button in the menu.

Will execute code and display result below, or render markup etc.
import datetime
print("This code is run right now (" + str(datetime.datetime.now()) + ")")
'hi'
This code is run right now (2019-05-27 11:40:46.125299)
'hi'
x=1+2+2
print(x)
5
Python Help Tips¶
- Get help on a function or object via
[shift] + [tab]after the opening parenthesisfunction(

- Can also get help by executing
function?

Python Natural Language Toolkit (NLTK)¶
import nltk
help(nltk)
Help on package nltk:
NAME
nltk
DESCRIPTION
The Natural Language Toolkit (NLTK) is an open source Python library
for Natural Language Processing. A free online book is available.
(If you use the library for academic research, please cite the book.)
Steven Bird, Ewan Klein, and Edward Loper (2009).
Natural Language Processing with Python. O'Reilly Media Inc.
http://nltk.org/book
@version: 3.4.1
PACKAGE CONTENTS
app (package)
book
ccg (package)
chat (package)
chunk (package)
classify (package)
cluster (package)
collections
collocations
compat
corpus (package)
data
decorators
downloader
draw (package)
featstruct
grammar
help
inference (package)
internals
jsontags
lazyimport
lm (package)
metrics (package)
misc (package)
parse (package)
probability
sem (package)
sentiment (package)
stem (package)
tag (package)
tbl (package)
test (package)
text
tgrep
tokenize (package)
toolbox
translate (package)
tree
treeprettyprinter
treetransforms
twitter (package)
util
wsd
SUBMODULES
agreement
aline
api
association
bleu_score
bllip
boxer
brill
brill_trainer
casual
chart
cistem
confusionmatrix
corenlp
crf
decisiontree
dependencygraph
discourse
distance
drt
earleychart
evaluate
featurechart
glue
hmm
hunpos
ibm1
ibm2
ibm3
ibm4
ibm5
ibm_model
isri
lancaster
lfg
linearlogic
logic
mace
malt
mapping
maxent
megam
meteor_score
mwe
naivebayes
nltk.corpus
nonprojectivedependencyparser
paice
pchart
perceptron
porter
positivenaivebayes
projectivedependencyparser
prover9
punkt
recursivedescent
regexp
relextract
repp
resolution
ribes_score
rslp
rte_classify
scikitlearn
scores
segmentation
senna
sequential
sexpr
shiftreduce
simple
snowball
spearman
stack_decoder
stanford
stanford_segmenter
tableau
tadm
textcat
texttiling
tnt
toktok
transitionparser
treebank
viterbi
weka
wordnet
FUNCTIONS
demo()
# FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116
DATA
RUS_PICKLE = 'taggers/averaged_perceptron_tagger_ru/averaged_perceptro...
SLASH = *slash*
TYPE = *type*
__author_email__ = 'stevenbird1@gmail.com'
__classifiers__ = ['Development Status :: 5 - Production/Stable', 'Int...
__copyright__ = 'Copyright (C) 2001-2019 NLTK Project.\n\nDistribut......
__keywords__ = ['NLP', 'CL', 'natural language processing', 'computati...
__license__ = 'Apache License, Version 2.0'
__longdescr__ = 'The Natural Language Toolkit (NLTK) is a Python ... p...
__maintainer__ = 'Steven Bird, Edward Loper, Ewan Klein'
__maintainer_email__ = 'stevenbird1@gmail.com'
__url__ = 'http://nltk.org/'
absolute_import = _Feature((2, 5, 0, 'alpha', 1), (3, 0, 0, 'alpha', 0...
app = <LazyModule 'nltk.nltk.app'>
chat = <LazyModule 'nltk.nltk.chat'>
class_types = (<class 'type'>,)
corpus = <LazyModule 'nltk.corpus'>
improved_close_quote_regex = re.compile('([»”’])')
improved_open_quote_regex = re.compile('([«“‘„]|[`]+)')
improved_open_single_quote_regex = re.compile("(?i)(\\')(?!re|ve|ll|m|...
improved_punct_regex = re.compile('([^\\.])(\\.)([\\]\\)}>"\\\'»”’ ]*)...
infile = <_io.TextIOWrapper name='/home/user01/anaconda3/...packages/n...
json_tags = {'!nltk.tag.BrillTagger': <class 'nltk.tag.brill.BrillTagg...
print_function = _Feature((2, 6, 0, 'alpha', 2), (3, 0, 0, 'alpha', 0)...
string_types = (<class 'str'>,)
toolbox = <LazyModule 'nltk.nltk.toolbox'>
version_file = '/home/user01/anaconda3/envs/slides/lib/python3.7/site-...
version_info = sys.version_info(major=3, minor=7, micro=3, releaseleve...
VERSION
3.4.1
AUTHOR
Steven Bird, Edward Loper, Ewan Klein
FILE
/home/user01/anaconda3/envs/slides/lib/python3.7/site-packages/nltk/__init__.py
What is NLTK?¶
Natural Language Toolkit (nltk) is a Python package for NLP
Pros:
- Common
- Functionality
Cons:
- Too academic
- Too slow
- Awkward API
We'll be using NLTK a lot (but also other more modern libraries).
What are Corpus / Corpora?¶
a collection of written texts, especially the entire works of a particular author or a body of writing on a particular subject.
The rest of the world call them "documents".
I have curated corpora for you.
Download nltk corpora (3.4GB)¶
nltk.download('all')
[nltk_data] Downloading collection 'all' [nltk_data] | [nltk_data] | Downloading package abc to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/abc.zip. [nltk_data] | Downloading package alpino to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/alpino.zip. [nltk_data] | Downloading package biocreative_ppi to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/biocreative_ppi.zip. [nltk_data] | Downloading package brown to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/brown.zip. [nltk_data] | Downloading package brown_tei to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/brown_tei.zip. [nltk_data] | Downloading package cess_cat to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/cess_cat.zip. [nltk_data] | Downloading package cess_esp to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/cess_esp.zip. [nltk_data] | Downloading package chat80 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/chat80.zip. [nltk_data] | Downloading package city_database to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/city_database.zip. [nltk_data] | Downloading package cmudict to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/cmudict.zip. [nltk_data] | Downloading package comparative_sentences to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/comparative_sentences.zip. [nltk_data] | Downloading package comtrans to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package conll2000 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/conll2000.zip. [nltk_data] | Downloading package conll2002 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/conll2002.zip. [nltk_data] | Downloading package conll2007 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package crubadan to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/crubadan.zip. [nltk_data] | Downloading package dependency_treebank to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/dependency_treebank.zip. [nltk_data] | Downloading package dolch to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/dolch.zip. [nltk_data] | Downloading package europarl_raw to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/europarl_raw.zip. [nltk_data] | Downloading package floresta to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/floresta.zip. [nltk_data] | Downloading package framenet_v15 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/framenet_v15.zip. [nltk_data] | Downloading package framenet_v17 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/framenet_v17.zip. [nltk_data] | Downloading package gazetteers to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/gazetteers.zip. [nltk_data] | Downloading package genesis to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/genesis.zip. [nltk_data] | Downloading package gutenberg to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/gutenberg.zip. [nltk_data] | Downloading package ieer to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/ieer.zip. [nltk_data] | Downloading package inaugural to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/inaugural.zip. [nltk_data] | Downloading package indian to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/indian.zip. [nltk_data] | Downloading package jeita to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package kimmo to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/kimmo.zip. [nltk_data] | Downloading package knbc to /home/user01/nltk_data... [nltk_data] | Downloading package lin_thesaurus to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/lin_thesaurus.zip. [nltk_data] | Downloading package mac_morpho to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/mac_morpho.zip. [nltk_data] | Downloading package machado to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package masc_tagged to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package moses_sample to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping models/moses_sample.zip. [nltk_data] | Downloading package movie_reviews to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/movie_reviews.zip. [nltk_data] | Downloading package names to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/names.zip. [nltk_data] | Downloading package nombank.1.0 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package nps_chat to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/nps_chat.zip. [nltk_data] | Downloading package omw to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/omw.zip. [nltk_data] | Downloading package opinion_lexicon to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/opinion_lexicon.zip. [nltk_data] | Downloading package paradigms to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/paradigms.zip. [nltk_data] | Downloading package pil to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/pil.zip. [nltk_data] | Downloading package pl196x to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/pl196x.zip. [nltk_data] | Downloading package ppattach to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/ppattach.zip. [nltk_data] | Downloading package problem_reports to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/problem_reports.zip. [nltk_data] | Downloading package propbank to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package ptb to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/ptb.zip. [nltk_data] | Downloading package product_reviews_1 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/product_reviews_1.zip. [nltk_data] | Downloading package product_reviews_2 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/product_reviews_2.zip. [nltk_data] | Downloading package pros_cons to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/pros_cons.zip. [nltk_data] | Downloading package qc to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/qc.zip. [nltk_data] | Downloading package reuters to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package rte to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/rte.zip. [nltk_data] | Downloading package semcor to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package senseval to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/senseval.zip. [nltk_data] | Downloading package sentiwordnet to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/sentiwordnet.zip. [nltk_data] | Downloading package sentence_polarity to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/sentence_polarity.zip. [nltk_data] | Downloading package shakespeare to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/shakespeare.zip. [nltk_data] | Downloading package sinica_treebank to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/sinica_treebank.zip. [nltk_data] | Downloading package smultron to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/smultron.zip. [nltk_data] | Downloading package state_union to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/state_union.zip. [nltk_data] | Downloading package stopwords to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/stopwords.zip. [nltk_data] | Downloading package subjectivity to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/subjectivity.zip. [nltk_data] | Downloading package swadesh to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/swadesh.zip. [nltk_data] | Downloading package switchboard to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/switchboard.zip. [nltk_data] | Downloading package timit to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/timit.zip. [nltk_data] | Downloading package toolbox to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/toolbox.zip. [nltk_data] | Downloading package treebank to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/treebank.zip. [nltk_data] | Downloading package twitter_samples to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/twitter_samples.zip. [nltk_data] | Downloading package udhr to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/udhr.zip. [nltk_data] | Downloading package udhr2 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/udhr2.zip. [nltk_data] | Downloading package unicode_samples to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/unicode_samples.zip. [nltk_data] | Downloading package universal_treebanks_v20 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package verbnet to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/verbnet.zip. [nltk_data] | Downloading package verbnet3 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/verbnet3.zip. [nltk_data] | Downloading package webtext to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/webtext.zip. [nltk_data] | Downloading package wordnet to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/wordnet.zip. [nltk_data] | Downloading package wordnet_ic to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/wordnet_ic.zip. [nltk_data] | Downloading package words to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/words.zip. [nltk_data] | Downloading package ycoe to /home/user01/nltk_data... [nltk_data] | Unzipping corpora/ycoe.zip. [nltk_data] | Downloading package rslp to /home/user01/nltk_data... [nltk_data] | Unzipping stemmers/rslp.zip. [nltk_data] | Downloading package maxent_treebank_pos_tagger to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping taggers/maxent_treebank_pos_tagger.zip. [nltk_data] | Downloading package universal_tagset to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping taggers/universal_tagset.zip. [nltk_data] | Downloading package maxent_ne_chunker to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping chunkers/maxent_ne_chunker.zip. [nltk_data] | Downloading package punkt to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping tokenizers/punkt.zip. [nltk_data] | Downloading package book_grammars to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping grammars/book_grammars.zip. [nltk_data] | Downloading package sample_grammars to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping grammars/sample_grammars.zip. [nltk_data] | Downloading package spanish_grammars to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping grammars/spanish_grammars.zip. [nltk_data] | Downloading package basque_grammars to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping grammars/basque_grammars.zip. [nltk_data] | Downloading package large_grammars to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping grammars/large_grammars.zip. [nltk_data] | Downloading package tagsets to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping help/tagsets.zip. [nltk_data] | Downloading package snowball_data to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package bllip_wsj_no_aux to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping models/bllip_wsj_no_aux.zip. [nltk_data] | Downloading package word2vec_sample to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping models/word2vec_sample.zip. [nltk_data] | Downloading package panlex_swadesh to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Downloading package mte_teip5 to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping corpora/mte_teip5.zip. [nltk_data] | Downloading package averaged_perceptron_tagger to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping taggers/averaged_perceptron_tagger.zip. [nltk_data] | Downloading package averaged_perceptron_tagger_ru to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Unzipping [nltk_data] | taggers/averaged_perceptron_tagger_ru.zip. [nltk_data] | Downloading package perluniprops to [nltk_data] | /home/user01/nltk_data... [nltk_data] | Error downloading 'perluniprops' from [nltk_data] | <https://raw.githubusercontent.com/nltk/nltk_data [nltk_data] | /gh-pages/packages/misc/perluniprops.zip>: [nltk_data] | <urlopen error [Errno 110] Connection timed out>
False
# Double check that you have the corpora
from nltk.corpus import genesis
print(genesis.words()[:5])
['In', 'the', 'beginning', 'God', 'created']
Python Textblob¶
import textblob
help(textblob)
Help on package textblob:
NAME
textblob
PACKAGE CONTENTS
_text
base
blob
classifiers
compat
decorators
download_corpora
en (package)
exceptions
formats
inflect
mixins
np_extractors
parsers
sentiments
taggers
tokenizers
translate
unicodecsv (package)
utils
wordnet
CLASSES
builtins.list(builtins.object)
textblob.blob.WordList
builtins.object
textblob.blob.Blobber
builtins.str(builtins.object)
textblob.blob.Word
textblob.blob.BaseBlob(textblob.mixins.StringlikeMixin, textblob.mixins.BlobComparableMixin)
textblob.blob.Sentence
textblob.blob.TextBlob
class Blobber(builtins.object)
| Blobber(tokenizer=None, pos_tagger=None, np_extractor=None, analyzer=None, parser=None, classifier=None)
|
| A factory for TextBlobs that all share the same tagger,
| tokenizer, parser, classifier, and np_extractor.
|
| Usage:
|
| >>> from textblob import Blobber
| >>> from textblob.taggers import NLTKTagger
| >>> from textblob.tokenizers import SentenceTokenizer
| >>> tb = Blobber(pos_tagger=NLTKTagger(), tokenizer=SentenceTokenizer())
| >>> blob1 = tb("This is one blob.")
| >>> blob2 = tb("This blob has the same tagger and tokenizer.")
| >>> blob1.pos_tagger is blob2.pos_tagger
| True
|
| :param tokenizer: (optional) A tokenizer instance. If ``None``,
| defaults to :class:`WordTokenizer() <textblob.tokenizers.WordTokenizer>`.
| :param np_extractor: (optional) An NPExtractor instance. If ``None``,
| defaults to :class:`FastNPExtractor() <textblob.en.np_extractors.FastNPExtractor>`.
| :param pos_tagger: (optional) A Tagger instance. If ``None``,
| defaults to :class:`NLTKTagger <textblob.en.taggers.NLTKTagger>`.
| :param analyzer: (optional) A sentiment analyzer. If ``None``,
| defaults to :class:`PatternAnalyzer <textblob.en.sentiments.PatternAnalyzer>`.
| :param parser: A parser. If ``None``, defaults to
| :class:`PatternParser <textblob.en.parsers.PatternParser>`.
| :param classifier: A classifier.
|
| .. versionadded:: 0.4.0
|
| Methods defined here:
|
| __call__(self, text)
| Return a new TextBlob object with this Blobber's ``np_extractor``,
| ``pos_tagger``, ``tokenizer``, ``analyzer``, and ``classifier``.
|
| :returns: A new :class:`TextBlob <TextBlob>`.
|
| __init__(self, tokenizer=None, pos_tagger=None, np_extractor=None, analyzer=None, parser=None, classifier=None)
| Initialize self. See help(type(self)) for accurate signature.
|
| __repr__(self)
| Return repr(self).
|
| __str__ = __repr__(self)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| analyzer = <textblob.en.sentiments.PatternAnalyzer object>
|
| np_extractor = <textblob.en.np_extractors.FastNPExtractor object>
|
| parser = <textblob.en.parsers.PatternParser object>
|
| pos_tagger = <textblob.en.taggers.NLTKTagger object>
|
| tokenizer = <textblob.tokenizers.WordTokenizer object>
class Sentence(BaseBlob)
| Sentence(sentence, start_index=0, end_index=None, *args, **kwargs)
|
| A sentence within a TextBlob. Inherits from :class:`BaseBlob <BaseBlob>`.
|
| :param sentence: A string, the raw sentence.
| :param start_index: An int, the index where this sentence begins
| in a TextBlob. If not given, defaults to 0.
| :param end_index: An int, the index where this sentence ends in
| a TextBlob. If not given, defaults to the
| length of the sentence - 1.
|
| Method resolution order:
| Sentence
| BaseBlob
| textblob.mixins.StringlikeMixin
| textblob.mixins.BlobComparableMixin
| textblob.mixins.ComparableMixin
| builtins.object
|
| Methods defined here:
|
| __init__(self, sentence, start_index=0, end_index=None, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| dict
| The dict representation of this sentence.
|
| ----------------------------------------------------------------------
| Methods inherited from BaseBlob:
|
| __add__(self, other)
| Concatenates two text objects the same way Python strings are
| concatenated.
|
| Arguments:
| - `other`: a string or a text object
|
| __hash__(self)
| Return hash(self).
|
| classify(self)
| Classify the blob using the blob's ``classifier``.
|
| correct(self)
| Attempt to correct the spelling of a blob.
|
| .. versionadded:: 0.6.0
|
| :rtype: :class:`BaseBlob <BaseBlob>`
|
| detect_language(self)
| Detect the blob's language using the Google Translate API.
|
| Requires an internet connection.
|
| Usage:
| ::
|
| >>> b = TextBlob("bonjour")
| >>> b.detect_language()
| u'fr'
|
| Language code reference:
| https://developers.google.com/translate/v2/using_rest#language-params
|
| .. versionadded:: 0.5.0
|
| :rtype: str
|
| ngrams(self, n=3)
| Return a list of n-grams (tuples of n successive words) for this
| blob.
|
| :rtype: List of :class:`WordLists <WordList>`
|
| noun_phrases = <textblob.decorators.cached_property object>
| np_counts = <textblob.decorators.cached_property object>
| parse(self, parser=None)
| Parse the text.
|
| :param parser: (optional) A parser instance. If ``None``, defaults to
| this blob's default parser.
|
| .. versionadded:: 0.6.0
|
| polarity = <textblob.decorators.cached_property object>
| pos_tags = <textblob.decorators.cached_property object>
| sentiment = <textblob.decorators.cached_property object>
| sentiment_assessments = <textblob.decorators.cached_property object>
| split(self, sep=None, maxsplit=9223372036854775807)
| Behaves like the built-in str.split() except returns a
| WordList.
|
| :rtype: :class:`WordList <WordList>`
|
| subjectivity = <textblob.decorators.cached_property object>
| tags = <textblob.decorators.cached_property object>
| tokenize(self, tokenizer=None)
| Return a list of tokens, using ``tokenizer``.
|
| :param tokenizer: (optional) A tokenizer object. If None, defaults to
| this blob's default tokenizer.
|
| tokens = <textblob.decorators.cached_property object>
| translate(self, from_lang='auto', to='en')
| Translate the blob to another language.
| Uses the Google Translate API. Returns a new TextBlob.
|
| Requires an internet connection.
|
| Usage:
| ::
|
| >>> b = TextBlob("Simple is better than complex")
| >>> b.translate(to="es")
| TextBlob('Lo simple es mejor que complejo')
|
| Language code reference:
| https://developers.google.com/translate/v2/using_rest#language-params
|
| .. versionadded:: 0.5.0.
|
| :param str from_lang: Language to translate from. If ``None``, will attempt
| to detect the language.
| :param str to: Language to translate to.
| :rtype: :class:`BaseBlob <BaseBlob>`
|
| word_counts = <textblob.decorators.cached_property object>
| words = <textblob.decorators.cached_property object>
| ----------------------------------------------------------------------
| Data and other attributes inherited from BaseBlob:
|
| analyzer = <textblob.en.sentiments.PatternAnalyzer object>
|
| np_extractor = <textblob.en.np_extractors.FastNPExtractor object>
|
| parser = <textblob.en.parsers.PatternParser object>
|
| pos_tagger = <textblob.en.taggers.NLTKTagger object>
|
| tokenizer = <textblob.tokenizers.WordTokenizer object>
|
| translator = <textblob.translate.Translator object>
|
| ----------------------------------------------------------------------
| Methods inherited from textblob.mixins.StringlikeMixin:
|
| __contains__(self, sub)
| Implements the `in` keyword like a Python string.
|
| __getitem__(self, index)
| Returns a substring. If index is an integer, returns a Python
| string of a single character. If a range is given, e.g. `blob[3:5]`,
| a new instance of the class is returned.
|
| __iter__(self)
| Makes the object iterable as if it were a string,
| iterating through the raw string's characters.
|
| __len__(self)
| Returns the length of the raw text.
|
| __repr__(self)
| Returns a string representation for debugging.
|
| __str__(self)
| Returns a string representation used in print statements
| or str(my_blob).
|
| ends_with = endswith(self, suffix, start=0, end=9223372036854775807)
|
| endswith(self, suffix, start=0, end=9223372036854775807)
| Returns True if the blob ends with the given suffix.
|
| find(self, sub, start=0, end=9223372036854775807)
| Behaves like the built-in str.find() method. Returns an integer,
| the index of the first occurrence of the substring argument sub in the
| sub-string given by [start:end].
|
| format(self, *args, **kwargs)
| Perform a string formatting operation, like the built-in
| `str.format(*args, **kwargs)`. Returns a blob object.
|
| index(self, sub, start=0, end=9223372036854775807)
| Like blob.find() but raise ValueError when the substring
| is not found.
|
| join(self, iterable)
| Behaves like the built-in `str.join(iterable)` method, except
| returns a blob object.
|
| Returns a blob which is the concatenation of the strings or blobs
| in the iterable.
|
| lower(self)
| Like str.lower(), returns new object with all lower-cased characters.
|
| replace(self, old, new, count=9223372036854775807)
| Return a new blob object with all the occurence of `old` replaced
| by `new`.
|
| rfind(self, sub, start=0, end=9223372036854775807)
| Behaves like the built-in str.rfind() method. Returns an integer,
| the index of he last (right-most) occurence of the substring argument
| sub in the sub-sequence given by [start:end].
|
| rindex(self, sub, start=0, end=9223372036854775807)
| Like blob.rfind() but raise ValueError when substring is not
| found.
|
| starts_with = startswith(self, prefix, start=0, end=9223372036854775807)
|
| startswith(self, prefix, start=0, end=9223372036854775807)
| Returns True if the blob starts with the given prefix.
|
| strip(self, chars=None)
| Behaves like the built-in str.strip([chars]) method. Returns
| an object with leading and trailing whitespace removed.
|
| title(self)
| Returns a blob object with the text in title-case.
|
| upper(self)
| Like str.upper(), returns new object with all upper-cased characters.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from textblob.mixins.StringlikeMixin:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from textblob.mixins.ComparableMixin:
|
| __eq__(self, other)
| Return self==value.
|
| __ge__(self, other)
| Return self>=value.
|
| __gt__(self, other)
| Return self>value.
|
| __le__(self, other)
| Return self<=value.
|
| __lt__(self, other)
| Return self<value.
|
| __ne__(self, other)
| Return self!=value.
class TextBlob(BaseBlob)
| TextBlob(text, tokenizer=None, pos_tagger=None, np_extractor=None, analyzer=None, parser=None, classifier=None, clean_html=False)
|
| A general text block, meant for larger bodies of text (esp. those
| containing sentences). Inherits from :class:`BaseBlob <BaseBlob>`.
|
| :param str text: A string.
| :param tokenizer: (optional) A tokenizer instance. If ``None``, defaults to
| :class:`WordTokenizer() <textblob.tokenizers.WordTokenizer>`.
| :param np_extractor: (optional) An NPExtractor instance. If ``None``,
| defaults to :class:`FastNPExtractor() <textblob.en.np_extractors.FastNPExtractor>`.
| :param pos_tagger: (optional) A Tagger instance. If ``None``, defaults to
| :class:`NLTKTagger <textblob.en.taggers.NLTKTagger>`.
| :param analyzer: (optional) A sentiment analyzer. If ``None``, defaults to
| :class:`PatternAnalyzer <textblob.en.sentiments.PatternAnalyzer>`.
| :param classifier: (optional) A classifier.
|
| Method resolution order:
| TextBlob
| BaseBlob
| textblob.mixins.StringlikeMixin
| textblob.mixins.BlobComparableMixin
| textblob.mixins.ComparableMixin
| builtins.object
|
| Methods defined here:
|
| sentences = <textblob.decorators.cached_property object>
| to_json(self, *args, **kwargs)
| Return a json representation (str) of this blob.
| Takes the same arguments as json.dumps.
|
| .. versionadded:: 0.5.1
|
| words = <textblob.decorators.cached_property object>
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| json
| The json representation of this blob.
|
| .. versionchanged:: 0.5.1
| Made ``json`` a property instead of a method to restore backwards
| compatibility that was broken after version 0.4.0.
|
| raw_sentences
| List of strings, the raw sentences in the blob.
|
| serialized
| Returns a list of each sentence's dict representation.
|
| ----------------------------------------------------------------------
| Methods inherited from BaseBlob:
|
| __add__(self, other)
| Concatenates two text objects the same way Python strings are
| concatenated.
|
| Arguments:
| - `other`: a string or a text object
|
| __hash__(self)
| Return hash(self).
|
| __init__(self, text, tokenizer=None, pos_tagger=None, np_extractor=None, analyzer=None, parser=None, classifier=None, clean_html=False)
| Initialize self. See help(type(self)) for accurate signature.
|
| classify(self)
| Classify the blob using the blob's ``classifier``.
|
| correct(self)
| Attempt to correct the spelling of a blob.
|
| .. versionadded:: 0.6.0
|
| :rtype: :class:`BaseBlob <BaseBlob>`
|
| detect_language(self)
| Detect the blob's language using the Google Translate API.
|
| Requires an internet connection.
|
| Usage:
| ::
|
| >>> b = TextBlob("bonjour")
| >>> b.detect_language()
| u'fr'
|
| Language code reference:
| https://developers.google.com/translate/v2/using_rest#language-params
|
| .. versionadded:: 0.5.0
|
| :rtype: str
|
| ngrams(self, n=3)
| Return a list of n-grams (tuples of n successive words) for this
| blob.
|
| :rtype: List of :class:`WordLists <WordList>`
|
| noun_phrases = <textblob.decorators.cached_property object>
| np_counts = <textblob.decorators.cached_property object>
| parse(self, parser=None)
| Parse the text.
|
| :param parser: (optional) A parser instance. If ``None``, defaults to
| this blob's default parser.
|
| .. versionadded:: 0.6.0
|
| polarity = <textblob.decorators.cached_property object>
| pos_tags = <textblob.decorators.cached_property object>
| sentiment = <textblob.decorators.cached_property object>
| sentiment_assessments = <textblob.decorators.cached_property object>
| split(self, sep=None, maxsplit=9223372036854775807)
| Behaves like the built-in str.split() except returns a
| WordList.
|
| :rtype: :class:`WordList <WordList>`
|
| subjectivity = <textblob.decorators.cached_property object>
| tags = <textblob.decorators.cached_property object>
| tokenize(self, tokenizer=None)
| Return a list of tokens, using ``tokenizer``.
|
| :param tokenizer: (optional) A tokenizer object. If None, defaults to
| this blob's default tokenizer.
|
| tokens = <textblob.decorators.cached_property object>
| translate(self, from_lang='auto', to='en')
| Translate the blob to another language.
| Uses the Google Translate API. Returns a new TextBlob.
|
| Requires an internet connection.
|
| Usage:
| ::
|
| >>> b = TextBlob("Simple is better than complex")
| >>> b.translate(to="es")
| TextBlob('Lo simple es mejor que complejo')
|
| Language code reference:
| https://developers.google.com/translate/v2/using_rest#language-params
|
| .. versionadded:: 0.5.0.
|
| :param str from_lang: Language to translate from. If ``None``, will attempt
| to detect the language.
| :param str to: Language to translate to.
| :rtype: :class:`BaseBlob <BaseBlob>`
|
| word_counts = <textblob.decorators.cached_property object>
| ----------------------------------------------------------------------
| Data and other attributes inherited from BaseBlob:
|
| analyzer = <textblob.en.sentiments.PatternAnalyzer object>
|
| np_extractor = <textblob.en.np_extractors.FastNPExtractor object>
|
| parser = <textblob.en.parsers.PatternParser object>
|
| pos_tagger = <textblob.en.taggers.NLTKTagger object>
|
| tokenizer = <textblob.tokenizers.WordTokenizer object>
|
| translator = <textblob.translate.Translator object>
|
| ----------------------------------------------------------------------
| Methods inherited from textblob.mixins.StringlikeMixin:
|
| __contains__(self, sub)
| Implements the `in` keyword like a Python string.
|
| __getitem__(self, index)
| Returns a substring. If index is an integer, returns a Python
| string of a single character. If a range is given, e.g. `blob[3:5]`,
| a new instance of the class is returned.
|
| __iter__(self)
| Makes the object iterable as if it were a string,
| iterating through the raw string's characters.
|
| __len__(self)
| Returns the length of the raw text.
|
| __repr__(self)
| Returns a string representation for debugging.
|
| __str__(self)
| Returns a string representation used in print statements
| or str(my_blob).
|
| ends_with = endswith(self, suffix, start=0, end=9223372036854775807)
|
| endswith(self, suffix, start=0, end=9223372036854775807)
| Returns True if the blob ends with the given suffix.
|
| find(self, sub, start=0, end=9223372036854775807)
| Behaves like the built-in str.find() method. Returns an integer,
| the index of the first occurrence of the substring argument sub in the
| sub-string given by [start:end].
|
| format(self, *args, **kwargs)
| Perform a string formatting operation, like the built-in
| `str.format(*args, **kwargs)`. Returns a blob object.
|
| index(self, sub, start=0, end=9223372036854775807)
| Like blob.find() but raise ValueError when the substring
| is not found.
|
| join(self, iterable)
| Behaves like the built-in `str.join(iterable)` method, except
| returns a blob object.
|
| Returns a blob which is the concatenation of the strings or blobs
| in the iterable.
|
| lower(self)
| Like str.lower(), returns new object with all lower-cased characters.
|
| replace(self, old, new, count=9223372036854775807)
| Return a new blob object with all the occurence of `old` replaced
| by `new`.
|
| rfind(self, sub, start=0, end=9223372036854775807)
| Behaves like the built-in str.rfind() method. Returns an integer,
| the index of he last (right-most) occurence of the substring argument
| sub in the sub-sequence given by [start:end].
|
| rindex(self, sub, start=0, end=9223372036854775807)
| Like blob.rfind() but raise ValueError when substring is not
| found.
|
| starts_with = startswith(self, prefix, start=0, end=9223372036854775807)
|
| startswith(self, prefix, start=0, end=9223372036854775807)
| Returns True if the blob starts with the given prefix.
|
| strip(self, chars=None)
| Behaves like the built-in str.strip([chars]) method. Returns
| an object with leading and trailing whitespace removed.
|
| title(self)
| Returns a blob object with the text in title-case.
|
| upper(self)
| Like str.upper(), returns new object with all upper-cased characters.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from textblob.mixins.StringlikeMixin:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from textblob.mixins.ComparableMixin:
|
| __eq__(self, other)
| Return self==value.
|
| __ge__(self, other)
| Return self>=value.
|
| __gt__(self, other)
| Return self>value.
|
| __le__(self, other)
| Return self<=value.
|
| __lt__(self, other)
| Return self<value.
|
| __ne__(self, other)
| Return self!=value.
class Word(builtins.str)
| Word(string, pos_tag=None)
|
| A simple word representation. Includes methods for inflection,
| translation, and WordNet integration.
|
| Method resolution order:
| Word
| builtins.str
| builtins.object
|
| Methods defined here:
|
| __init__(self, string, pos_tag=None)
| Initialize self. See help(type(self)) for accurate signature.
|
| __repr__(self)
| Return repr(self).
|
| __str__(self)
| Return str(self).
|
| correct(self)
| Correct the spelling of the word. Returns the word with the highest
| confidence using the spelling corrector.
|
| .. versionadded:: 0.6.0
|
| define(self, pos=None)
| Return a list of definitions for this word. Each definition
| corresponds to a synset for this word.
|
| :param pos: A part-of-speech tag to filter upon. If ``None``, definitions
| for all parts of speech will be loaded.
| :rtype: List of strings
|
| .. versionadded:: 0.7.0
|
| definitions = <textblob.decorators.cached_property object>
| detect_language(self)
| Detect the word's language using Google's Translate API.
|
| .. versionadded:: 0.5.0
|
| get_synsets(self, pos=None)
| Return a list of Synset objects for this word.
|
| :param pos: A part-of-speech tag to filter upon. If ``None``, all
| synsets for all parts of speech will be loaded.
|
| :rtype: list of Synsets
|
| .. versionadded:: 0.7.0
|
| lemma = <textblob.decorators.cached_property object>
| lemmatize(self, pos=None)
| Return the lemma for a word using WordNet's morphy function.
|
| :param pos: Part of speech to filter upon. If `None`, defaults to
| ``_wordnet.NOUN``.
|
| .. versionadded:: 0.8.1
|
| pluralize(self)
| Return the plural version of the word as a string.
|
| singularize(self)
| Return the singular version of the word as a string.
|
| spellcheck(self)
| Return a list of (word, confidence) tuples of spelling corrections.
|
| Based on: Peter Norvig, "How to Write a Spelling Corrector"
| (http://norvig.com/spell-correct.html) as implemented in the pattern
| library.
|
| .. versionadded:: 0.6.0
|
| stem(self, stemmer=<PorterStemmer>)
| Stem a word using various NLTK stemmers. (Default: Porter Stemmer)
|
| .. versionadded:: 0.12.0
|
| synsets = <textblob.decorators.cached_property object>
| translate(self, from_lang='auto', to='en')
| Translate the word to another language using Google's
| Translate API.
|
| .. versionadded:: 0.5.0
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(cls, string, pos_tag=None)
| Return a new instance of the class. It is necessary to override
| this method in order to handle the extra pos_tag argument in the
| constructor.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| LancasterStemmer = <LancasterStemmer>
|
| PorterStemmer = <PorterStemmer>
|
| SnowballStemmer = <nltk.stem.snowball.SnowballStemmer object>
|
| translator = <textblob.translate.Translator object>
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.str:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Use keyword.iskeyword() to test for reserved identifiers such as "def" and
| "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| Splits are done starting at the end of the string and working to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace remove.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods inherited from builtins.str:
|
| maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
class WordList(builtins.list)
| WordList(collection)
|
| A list-like collection of words.
|
| Method resolution order:
| WordList
| builtins.list
| builtins.object
|
| Methods defined here:
|
| __getitem__(self, key)
| Returns a string at the given index.
|
| __getslice__(self, i, j)
|
| __init__(self, collection)
| Initialize a WordList. Takes a collection of strings as
| its only argument.
|
| __repr__(self)
| Returns a string representation for debugging.
|
| __setitem__(self, index, obj)
| Places object at given index, replacing existing item. If the object
| is a string, inserts a :class:`Word <Word>` object.
|
| __str__(self)
| Returns a string representation for printing.
|
| append(self, obj)
| Append an object to end. If the object is a string, appends a
| :class:`Word <Word>` object.
|
| count(self, strg, case_sensitive=False, *args, **kwargs)
| Get the count of a word or phrase `s` within this WordList.
|
| :param strg: The string to count.
| :param case_sensitive: A boolean, whether or not the search is case-sensitive.
|
| extend(self, iterable)
| Extend WordList by appending elements from ``iterable``. If an element
| is a string, appends a :class:`Word <Word>` object.
|
| lemmatize(self)
| Return the lemma of each word in this WordList.
|
| lower(self)
| Return a new WordList with each word lower-cased.
|
| pluralize(self)
| Return the plural version of each word in this WordList.
|
| singularize(self)
| Return the single version of each word in this WordList.
|
| stem(self, *args, **kwargs)
| Return the stem for each word in this WordList.
|
| upper(self)
| Return a new WordList with each word upper-cased.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Methods inherited from builtins.list:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __gt__(self, value, /)
| Return self>value.
|
| __iadd__(self, value, /)
| Implement self+=value.
|
| __imul__(self, value, /)
| Implement self*=value.
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __reversed__(self, /)
| Return a reverse iterator over the list.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the list in memory, in bytes.
|
| clear(self, /)
| Remove all items from list.
|
| copy(self, /)
| Return a shallow copy of the list.
|
| index(self, value, start=0, stop=9223372036854775807, /)
| Return first index of value.
|
| Raises ValueError if the value is not present.
|
| insert(self, index, object, /)
| Insert object before index.
|
| pop(self, index=-1, /)
| Remove and return item at index (default last).
|
| Raises IndexError if list is empty or index is out of range.
|
| remove(self, value, /)
| Remove first occurrence of value.
|
| Raises ValueError if the value is not present.
|
| reverse(self, /)
| Reverse *IN PLACE*.
|
| sort(self, /, *, key=None, reverse=False)
| Stable sort *IN PLACE*.
|
| ----------------------------------------------------------------------
| Static methods inherited from builtins.list:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from builtins.list:
|
| __hash__ = None
DATA
__all__ = ['TextBlob', 'Word', 'Sentence', 'Blobber', 'WordList']
__license__ = 'MIT'
VERSION
0.15.3
AUTHOR
Steven Loria
FILE
/home/user01/anaconda3/envs/slides/lib/python3.7/site-packages/textblob/__init__.py
from textblob import TextBlob
text1 = '''
It’s too bad that some of the young people that were killed over the weekend
didn’t have guns attached to their [hip],
frankly, where bullets could have flown in the opposite direction...
'''
text2 = '''
A President and "world-class deal maker," marveled Frida Ghitis, who demonstrates
with a "temper tantrum," that he can't make deals. Who storms out of meetings with
congressional leaders while insisting he's calm (and lines up his top aides to confirm it for the cameras).
'''
blob1 = TextBlob(text1)
blob2 = TextBlob(text2)
blob1.words
WordList(['It', '’', 's', 'too', 'bad', 'that', 'some', 'of', 'the', 'young', 'people', 'that', 'were', 'killed', 'over', 'the', 'weekend', 'didn', '’', 't', 'have', 'guns', 'attached', 'to', 'their', 'hip', 'frankly', 'where', 'bullets', 'could', 'have', 'flown', 'in', 'the', 'opposite', 'direction'])
blob1.word_counts
defaultdict(int,
{'it': 1,
'’': 2,
's': 1,
'too': 1,
'bad': 1,
'that': 2,
'some': 1,
'of': 1,
'the': 3,
'young': 1,
'people': 1,
'were': 1,
'killed': 1,
'over': 1,
'weekend': 1,
'didn': 1,
't': 1,
'have': 2,
'guns': 1,
'attached': 1,
'to': 1,
'their': 1,
'hip': 1,
'frankly': 1,
'where': 1,
'bullets': 1,
'could': 1,
'flown': 1,
'in': 1,
'opposite': 1,
'direction': 1})
blob1.sentiment
Sentiment(polarity=-0.19999999999999996, subjectivity=0.26666666666666666)
blob2.sentiment
Sentiment(polarity=0.4, subjectivity=0.625)
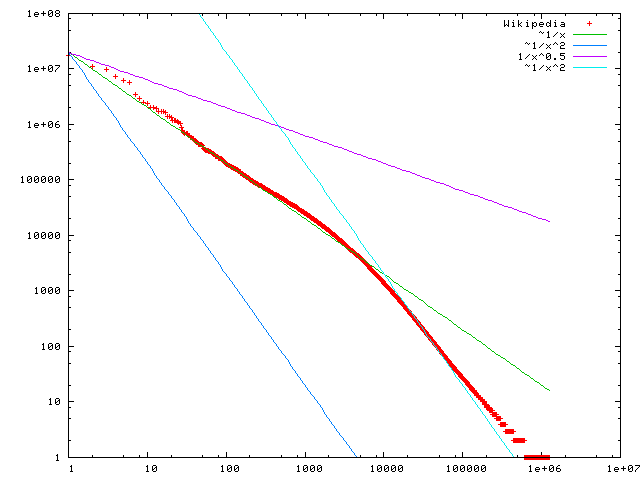
Activity: Zipf's Law¶
Zipf's law states that given a large sample of words used, the frequency of any word is inversely proportional to its rank in the frequency table. 2nd word is half as common as first word. Third word is 1/3 as common. Etc.
For example:
| Word | Rank | Frequency |
|---|---|---|
| “the” | 1st | 30k |
| "of" | 2nd | 15k |
| "and" | 3rd | 7.5k |

Plot word frequencies¶
from nltk.corpus import genesis
from collections import Counter
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(counts_sorted[:50]);

Does this confirm to Zipf Law? Why or Why not?
Activity Part 2: List the most common words¶
Activity Part 3: Remove punctuation¶
from string import punctuation
sample_clean = [item for item in sample if not item[0] in punctuation]
sample_clean
[('the', 4642),
('and', 4368),
('de', 3160),
('of', 2824),
('a', 2372),
('e', 2353),
('und', 2010),
('och', 1839),
('to', 1805),
('in', 1625)]
Activity Part 4: Null model¶
- Generate random text including the space character.
- Tokenize this string of gibberish
- Generate another plot of Zipf's
- Compare the two plots.
What do you make of Zipf's Law in the light of this?
How does your result compare to Wikipedia?¶